Last month, on Sept 10th, I finally finished the Capstone project for the tenth course of the Coursera Data Science Specialization. I had been staying up for more than four nights in a row, the latest to the second day at 5:30 am. I don’t remember when was last time I had done this since I graduated from my Ph.D. study.
I remember fighting one after another challenges during this project. For so many times, I felt that I might just not have the character to be a data scientist. I had made so many mistakes during the process, yet those were also how I learned. Bit by bit, I kept correcting, tweaking, and improving my program.
At one point, I thought I had a final product. Then I found that someone on the course forum had provided a benchmark program which can help test how well your app perform. Yet the process to plug in your own program to do the test itself was quite a bit of challenge.
In the end, I saw a lot of other assignments which didn’t even bother to do it. However, plugging in my app into this benchmark program forced me to compare my app’s performance to others, which in turn forced me to keep improving and debugging.
At the end, the result was satisfying: I created my own predict the next word app, and I am quite satisfied in comparison to the peers’ works that I have seen during the peer assignment reviewing:
https://maggiehu.shinyapps.io/NextWords/
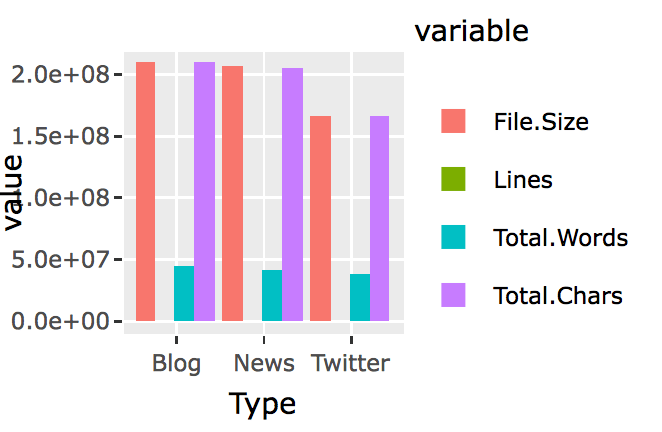
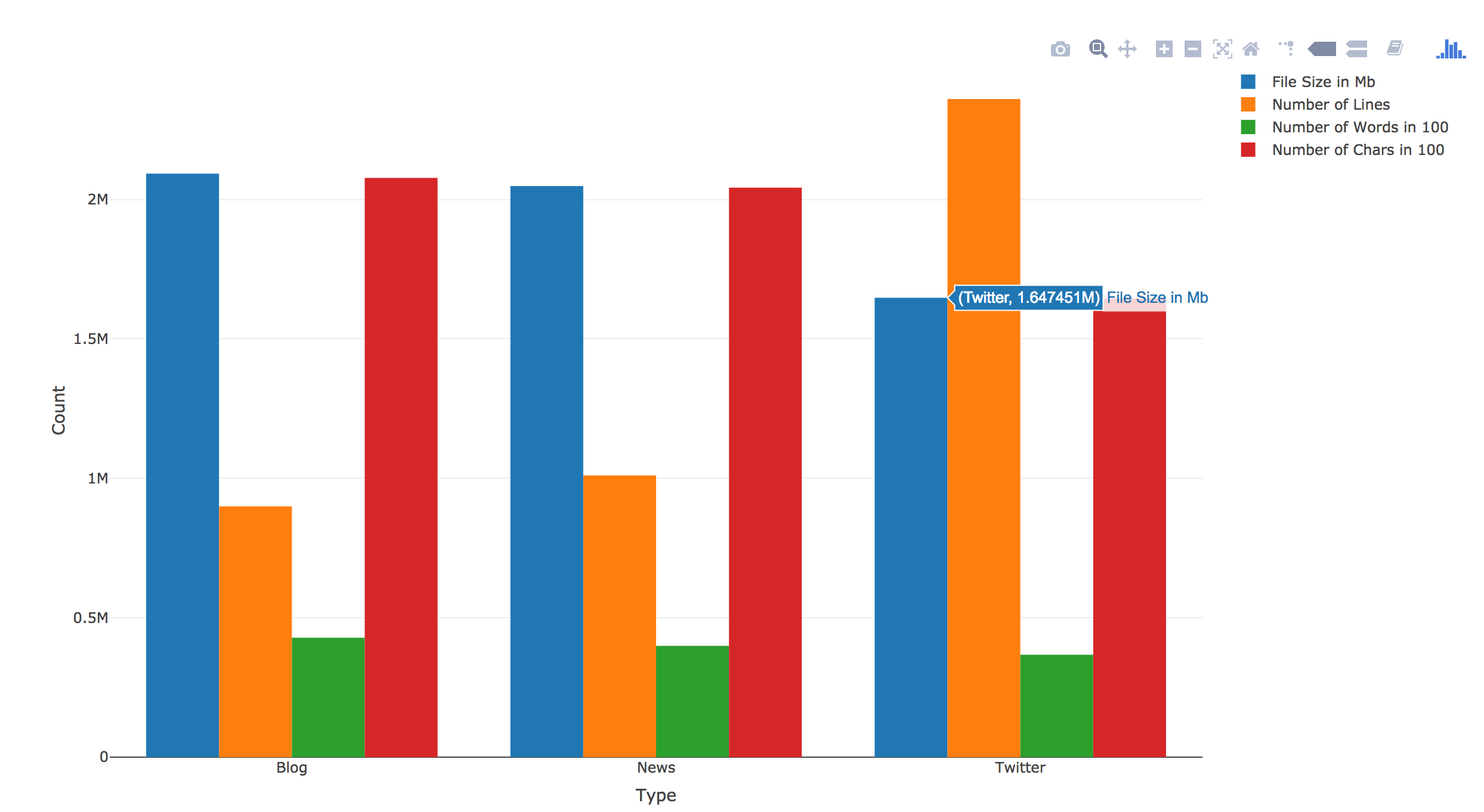
My app provides not only the top candidates for next word prediction, but also provides the weight of each candidate, using the Stupid Backoff method. I also tried to model after the cellphone text type prediction function, which allows the user to click on the preferred candidate to auto-fill the text box. Below is a screenshot of the predicted top candidate words, when you type in “what doesn’t” in the text box.
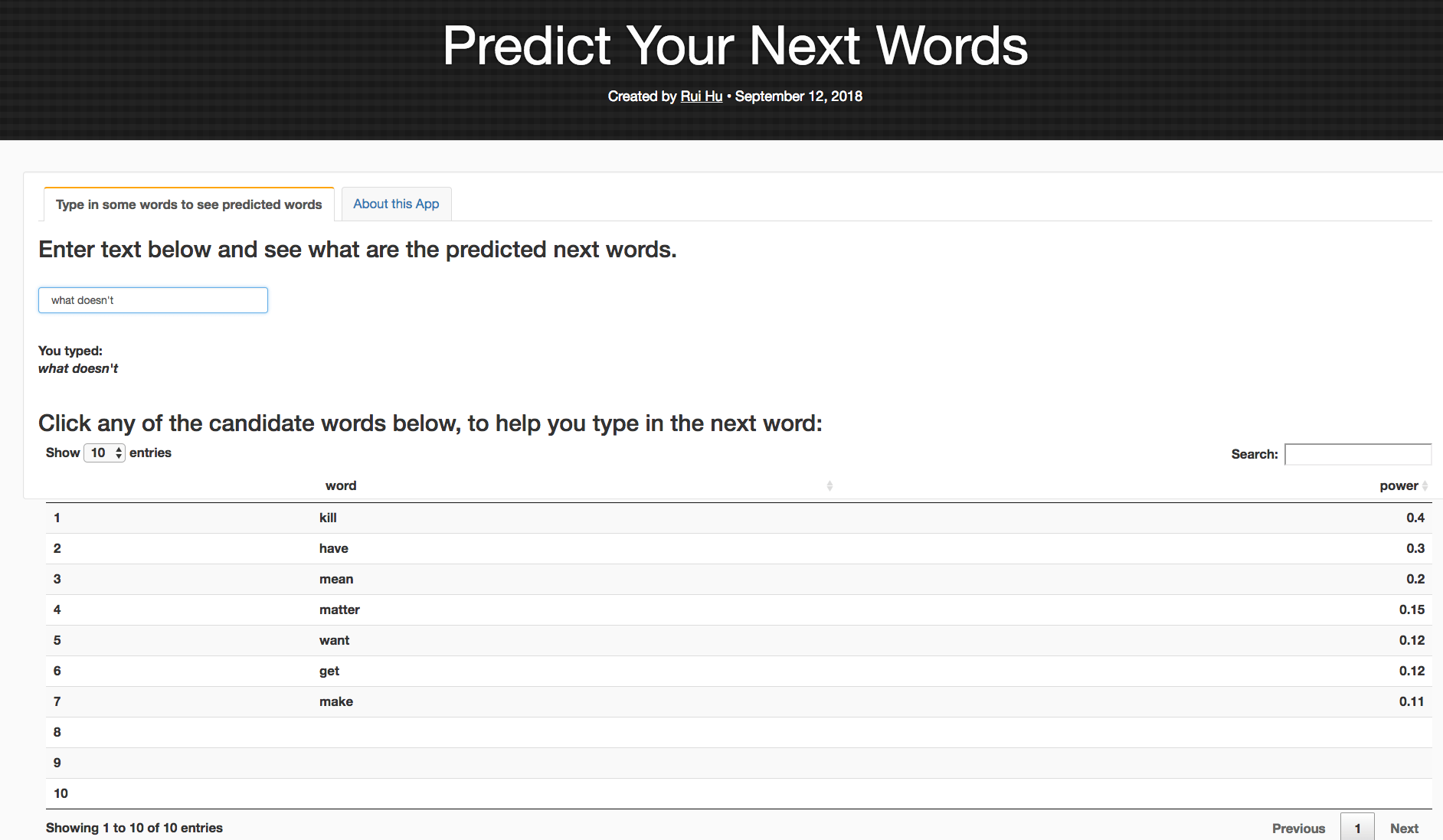
And here is the accompanied R presentation (The R Studio Presenter program implements very clumsy CSS styles which took me additional two hours, after the long marathon of debugging and tweaking the app itself. So I really wish that the course had not had this specific requirement of using R Studio Presenter for the course presentation.