But I didn’t dive deep into the third pillar that makes RAG truly powerful: metadata. While chunking handles the “what” of your content and embeddings capture the “meaning,” metadata provides the essential “context” that transforms good retrieval into precise, relevant results.
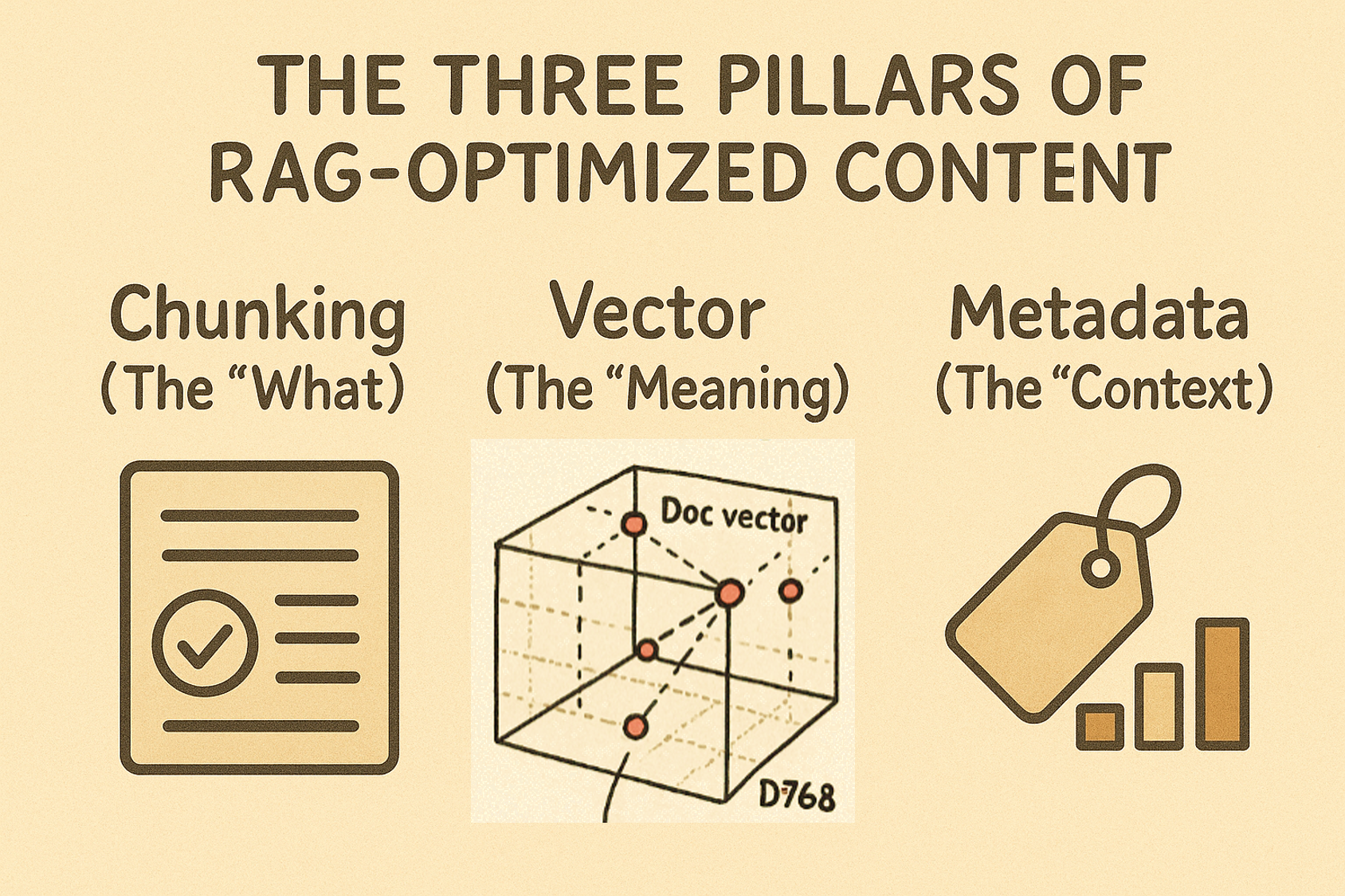
The Three Pillars of RAG-Optimized Content
Chunking (The “What”): Breaks content into digestible, topic-focused pieces
Structured formats with clear headings
Single-topic chunks
Consistent templates
Vector Embeddings (The “Meaning”): Captures semantic understanding
Question-format headings
Conversational language
Semantic similarity matching
Metadata (The “Context”): Provides situational relevance
Article type and intended audience
Skill level and role requirements
Date, version, and related topics
To understand why richer metadata can provide better context, we need to understand how vector embeddings are stored in vector database. After all, when RAG compare and retrieve chunks, it searches inside of the vector database to find semantic match.
So, what a vector record (the data entry) in a vector database looks like?
What’s Inside a Vector Record?
A vector record has three parts:
1. Unique ID A label that helps you quickly find the original content, which is stored separately.
2. The Vector A list of numbers that represents your content’s meaning (like a mathematical “fingerprint”). For example, text might become a list of 768 numbers.
Key rule: All vectors in the same collection must have the same length – you can’t mix different sizes.
3. Metadata Extra tags that add context, including:
How RAG Search Combines Vector Matching with Metadata Filtering
RAG (Retrieval-Augmented Generation) search combines vector similarity with metadata filtering to make your results both relevant and contextually appropriate. The RAG framework was first introduced by researchers at Meta in 2020 (see the original paper)::
Vector Similarity Matching When you ask a question, the system converts your question into a vector embedding (that same list of numbers we discussed). Then it searches the database for content vectors that are mathematically similar to your question vector. Think of it like finding documents that “mean” similar things to what you’re asking about.
Metadata Context Enhancement The system enhances similarity matching by also considering metadata context. These metadata filters can be set by users (when they specify requirements) or automatically by the system (based on context clues in the query). The system considers:
Time relevance: “Only show me recent information from 2023 or later”
Source credibility: “Only include content from verified authors or trusted platforms”
Content type: “Focus on technical documentation, not blog posts”
Geographic relevance: “Prioritize information relevant to my location”
This combined approach is also more efficient – metadata filtering can quickly eliminate irrelevant content before expensive similarity calculations.
The Combined Power Instead of getting thousands of somewhat-related results, you get a curated set of content that is both:
Semantically similar (the vector embeddings match your question’s meaning)
Contextually appropriate (the metadata ensures it meets your specific requirements)
For example, when you ask “How do I optimize database performance?” the system finds semantically similar content, then prioritizes results that match your context – returning recent technical articles by database experts while filtering out outdated blog posts or marketing content. You get the authoritative, current information you need.
What This Means for Content Creators
Understanding how metadata works in RAG systems reveals a crucial opportunity for content creators. Among the three types of metadata stored in vector databases, only one is truly under your control:
Automatically Generated Metadata:
Chunk metadata: Created during content processing (chunk size, position, relationships)
Platform metadata: Added by publishing systems (creation date, source URL, file type)
Creator-Controlled Metadata:
Universal metadata: The contextual information you can strategically add to improve intent alignment
This is where you can make the biggest impact. By enriching your content with universal metadata, you help RAG systems understand not just what your content says, but who it’s for and how it should be used:
When you provide this contextual metadata, you’re essentially helping RAG systems deliver your content to the right person, at the right time, for the right purpose. The technical foundation we’ve explored – vector similarity plus metadata filtering – becomes much more powerful when content creators take advantage of universal metadata to improve intent alignment.
Your content doesn’t just need to be semantically relevant; it needs to be contextually perfect. Universal metadata is how you achieve that precision.
If you’ve used ChatGPT or Copilot and received an answer that sounded confident but was completely wrong, you’ve experienced a hallucination. These misleading outputs are a known challenge in generative AI—and while some causes are technical, others are surprisingly content-driven.
As a content creator, you might think hallucinations are out of your hands. But here’s the truth: you have more influence than you realize.
Let’s break it down.
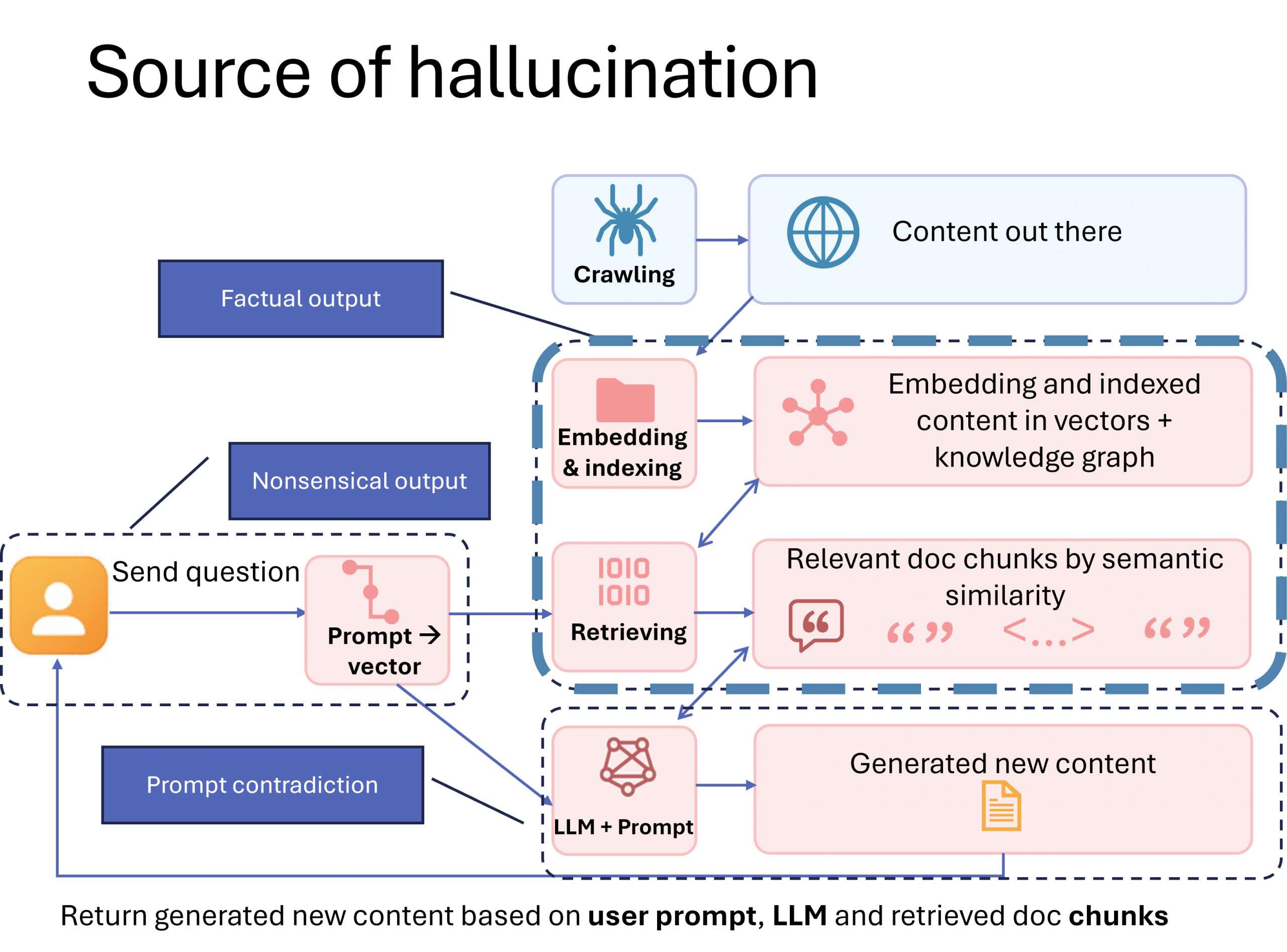
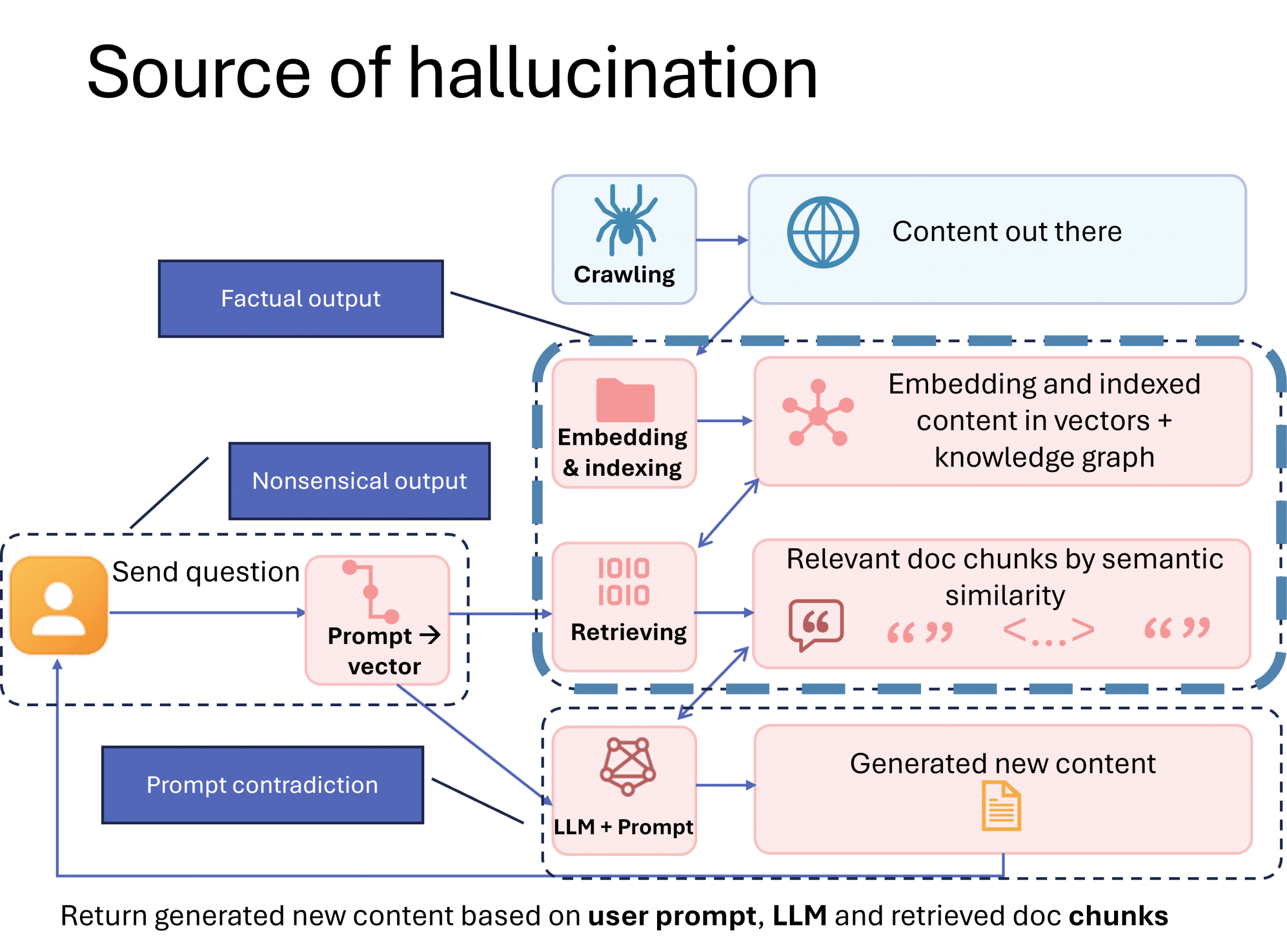
The Three Types of Hallucinations (And Where You Fit In)
Generative AI hallucinations typically fall into three practical categories. (Note: Academic research classifies these as “intrinsic” hallucinations that contradict the source/prompt, or “extrinsic” hallucinations that add unverifiable information. Our framework translates these concepts into actionable categories for content creators.)
Nonsensical Output The AI produces content that’s vague, incoherent, or just doesn’t make sense. Cause: Poorly written or ambiguous prompts. Your Role: Help users write better prompts by providing examples, templates, or guidance.
Factual Contradiction The AI gives answers that are clear and confident—but wrong, outdated, or misleading. Cause: The AI can’t find accurate or relevant information to base its response on. Your Role: Create high-quality, domain-specific content that’s easy for AI to find and understand.
Prompt Contradiction The AI’s response contradicts the user’s prompt, often due to internal safety filters or misalignment. Cause: Model-level restrictions or misinterpretation. Your Role: Limited—this is mostly a model design issue.
Where Does AI Get Its Information?
Where Does AI Get Its Information?
Modern AI systems increasingly use RAG (Retrieval-Augmented Generation) to ground their responses in real data. Instead of relying solely on training data, they actively search for and retrieve relevant content before generating answers. Learn more about how AI discovers and synthesizes content.
If your content is published online, it becomes part of the “source of truth” that AI systems rely on. That means your work directly affects whether AI gives accurate answers—or hallucinates.
The Discovery–Accuracy Loop
Here’s how it works:
If AI can’t find relevant content → it guesses based on general training data.
If AI finds partial content → it fills in the gaps with assumptions.
If AI finds complete and relevant content → it delivers accurate answers.
So what does this mean for you?
Your Real Impact as a Content Creator
You can’t control how AI is trained, but you can control two critical things:
The quality of content available for retrieval
The likelihood that your content gets discovered and indexed
And here’s the key insight:
This is where content creators have the greatest impact—by ensuring that content is not only high-quality and domain-specific, but also structured into discoverable chunks that AI systems can retrieve and interpret accurately.
Think of it like this: if your content is buried in long paragraphs, lacks clear headings, or isn’t tagged properly, AI might miss it—or misinterpret it. But if it’s chunked into clear, well-labeled sections, it’s far more likely to be picked up and used correctly. This shift from keywords to chunks is fundamental to how AI indexing differs from traditional search.
Actionable Tips for AI-Optimized Content
Structure for Chunking
Use clear, descriptive headings that summarize the content below them
Write headings as questions when possible (“How does X work?” instead of “X Overview”)
Keep paragraphs focused on single concepts (3–5 sentences max)
Create semantic sections that can stand alone as complete thoughts
Include Q&A pairs for common queries—this mirrors how users interact with AI
Use bullet points and numbered lists to break down complex information
Improve Discoverability
Front-load key information in each section—AI often prioritizes early content
Define technical terms clearly within your content, not just in glossaries
Include contextual metadata through schema markup and structured data
Write descriptive alt text for images and diagrams
Enhance Accuracy
Date your content clearly, especially for time-sensitive information
Link related concepts within your content to provide context
Be explicit about scope —what your content covers and what it doesn’t
Think about the deeper purpose behind a search. Are users trying to solve a problem? Make a decision? Learn a concept? Your content should reflect that.
The Bottom Line
As AI continues to evolve from retrieval to generative systems, your role as a content creator becomes more critical—not less. By structuring your content for AI discoverability and comprehension, you’re not just improving search rankings; you’re actively reducing the likelihood that AI will hallucinate when answering questions in your domain.
So the next time you create or update content, ask yourself:
“Can an AI system easily find, understand, and accurately use this information?”
If the answer is yes, you’re part of the solution.
In my earlier post, I explained the fundamental shift from traditional search to generative AI search. Traditional search finds existing content. Generative AI creates new responses.
If you’ve been hearing recommendations about “AI-ready content” like chunk-sized content, conversational language, Q&A formats, and structured writing, these probably sound familiar. As instructional designers and content developers, we’ve used most of these approaches for years. We chunk content for better learning, write conversationally to engage readers, and use metadata for reporting and semantic web purposes.
Today, I want to examine how this shift starts at the very beginning: when systems index and process content.
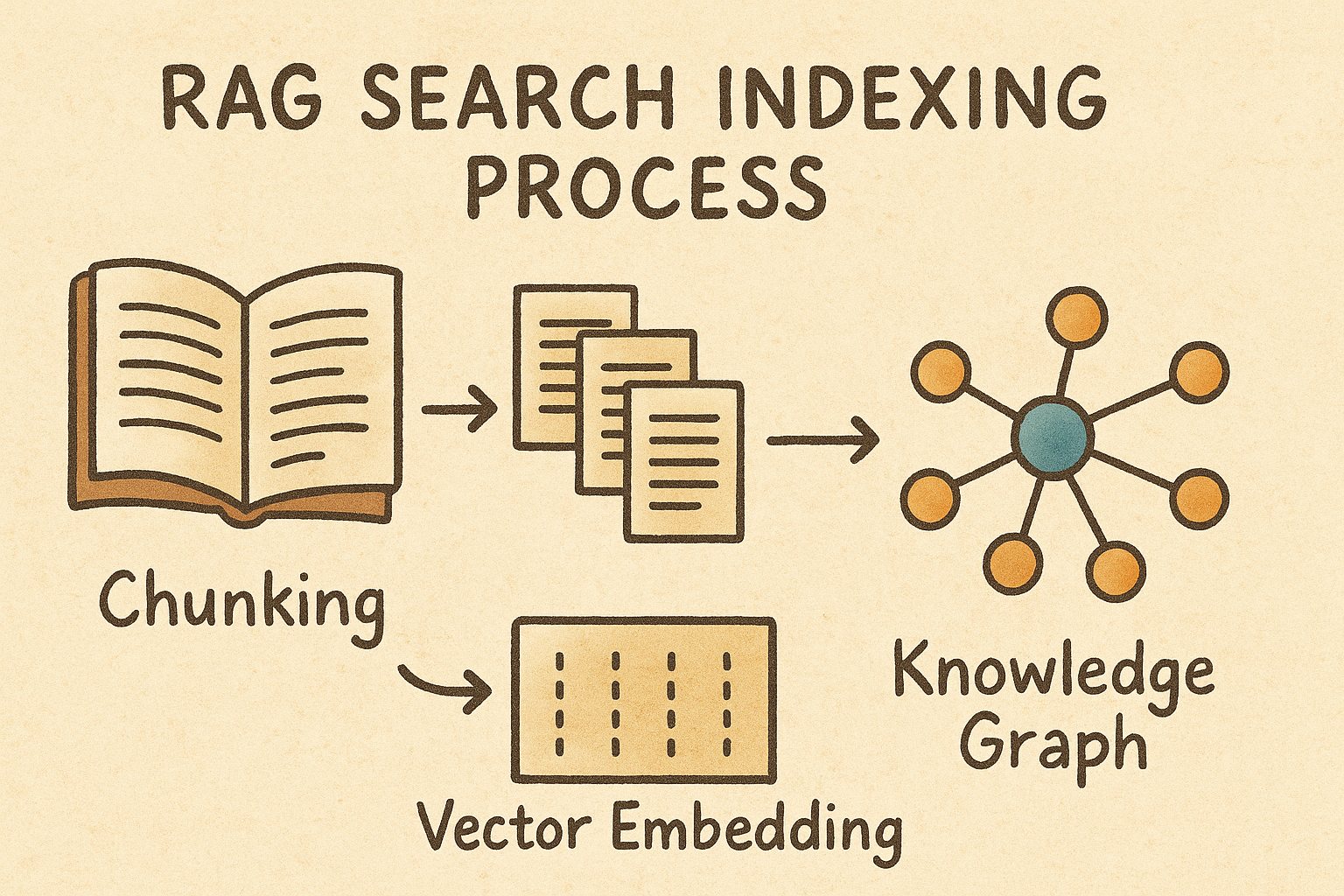
What is Indexing?
Indexing is how search systems break down and organize content to make it searchable. Traditional search creates keyword indexes, while AI search creates vector embeddings and knowledge graphs from semantic chunks. The move from keywords to chunks signifies one of the most significant changes in how search technology works.
Let’s trace how both systems process the same content using three sample documents from my previous post:
Document 1: “Upgrading your computer's hard drive to a solid-state drive (SSD) can dramatically improve performance. SSDs provide faster boot times and quicker file access compared to traditional drives.“
Document 2: “Slow computer performance is often caused by too many programs running simultaneously. Close unnecessary background programs and disable startup applications to fix speed issues.“
Document 3: “Regular computer maintenance prevents performance problems. Clean temporary files, update software, and run system diagnostics to keep your computer running efficiently.“
User query: “How to make my computer faster?“
How does traditional search index content?
Traditional search follows three mechanical steps:
Step 1: Tokenization
This step breaks raw text into individual words. The three docs after tokenization look like this:
Stop words are common words that appear frequently in text but carry little meaningful information for search purposes. They’re typically removed during text preprocessing to focus on content-bearing words.
Common English stop words:
a, an, the, is, are, was, were, be, been, being, have, has, had, do, does, did, will, would, could, should, may, might, can, of, in, on, at, by, for, with, to, from, up, down, into, over, under, and, or, but, not, no, yes, this, that, these, those, here, there, when, where, why, how, what, who, which, your, my, our, their
What is Stemming?
Stemming is the process of reducing words to their root form by removing suffixes, prefixes, and other word endings. The goal is to treat different forms of the same word as identical for search purposes.
Some stemming Examples:
Original Word → Stemmed Form
"running" → "run"
"runs" → "run"
"runner" → "run"
"performance" → "perform"
"performed" → "perform"
"performing" → "perform"
The three sample documents after stop words removal and stemming look like this:
An inverted index is like a book’s index, but instead of mapping topics to page numbers, it maps each unique word to all the documents that contain it. It’s called “inverted” because instead of going from documents to words, it goes from words to documents.
Note: For clarity and space, I’m showing only a representative subset that demonstrates key patterns.
The complete inverted index would contain entries for all ~28 unique terms from our processed documents. The key patterns include:
Terms appearing in all documents (common terms like “comput”)
Terms unique to one document (distinctive terms like “ssd”)
Terms with varying frequencies (like “program” with tf=2)
The result: An inverted index that maps each word to the documents containing it, along with frequency counts.
Why inverted indexing matters for content creators:
Traditional search relies on keyword matching. This is why SEO focused on keyword density and exact phrase matching.
How do AI systems index content?
AI systems take a fundamentally different approach:
Step 1: Semantic chunking
AI doesn’t break content into words. Instead, it creates meaningful, self-contained chunks. AI systems analyze content for topic boundaries, logical sections, and complete thoughts to determine where to split content. They look for natural break points that preserve context and meaning.
What AI Systems Look For When Chunking
1. Semantic Coherence
Topic consistency: Does this section maintain the same subject matter?
Conceptual relationships: Are these sentences talking about related ideas?
Context dependency: Do these sentences need each other to make sense?
2. Structural Signals
HTML tags: Headings (H1, H2, H3), paragraphs, lists, sections
Formatting cues: Line breaks, bullet points, numbered steps
Visual hierarchy: How content is organized on the page
Pronoun references: “It,” “This,” “These” that refer to previous concepts
Discourse markers: Words that signal topic shifts or continuations
4. Completeness of Information
Self-contained units: Can this chunk answer a question independently?
Context sufficiency: Does the chunk have enough background to be understood?
Action completeness: For instructions, does it contain a complete process?
5. Optimal Size Constraints
Token limits: Most AI models have processing windows (512, 1024, 4096 tokens)
Embedding efficiency: Chunks need to be small enough for accurate vector representation
Memory constraints: Balance between context preservation and processing speed
6. Content Type Recognition
Question-answer pairs: Natural chunk boundaries
Step-by-step instructions: Each step or related steps become chunks
Examples and explanations: Keep examples with their explanations
Lists and enumerations: Group related list items
For demonstration purposes, I’m breaking our sample documents by sentences, though real AI systems use more sophisticated semantic analysis:
DOC1 → Chunk 1A: "Upgrading your computer's hard drive to a solid-state drive (SSD) can dramatically improve performance."
DOC1 → Chunk 1B: "SSDs provide faster boot times and quicker file access compared to traditional drives."
DOC2 → Chunk 2A: "Slow computer performance is often caused by too many programs running simultaneously."
DOC2 → Chunk 2B: "Close unnecessary background programs and disable startup applications to fix speed issues."
DOC3 → Chunk 3A: "Regular computer maintenance prevents performance problems."
DOC3 → Chunk 3B: "Clean temporary files, update software, and run system diagnostics to keep your computer running efficiently."
Step 2: Vector embedding
Vector embeddings are created using pre-trained transformer neural networks like BERT, RoBERTa, or Sentence-BERT. These models have already learned semantic relationships from massive text datasets. Chunks are tokenized first, then passed through the pre-trained models. After that, each chunk becomes a mathematical representation of meaning.
Screenshot of the visualized knowledge graph based on the sample docs
A knowledge graph is a structured way to represent information as a network of connected entities and their relationships. Think of it like a map that shows how different concepts relate to each other. For example, it captures that “SSD improves performance” or “too many programs cause slowness.” This explicit relationship mapping helps AI systems understand not just what words appear together, but how concepts actually connect and influence each other.
How is knowledge graph constructed?
The system analyzes each text chunk to identify: (1) Entities – the important “things” mentioned (like Computer, SSD, Performance), (2) Relationships – how these things connect to each other (like “SSD improves Performance”), and (3) Entity Types – what category each entity belongs to (Hardware, Software, Metric, Process). These extracted elements are then linked together to form a web of knowledge that captures the logical structure of the information.
Vector embeddings and knowledge graphs work together as complementary approaches. Vector embeddings capture implicit semantic similarities (chunks about “SSD benefits” and “computer speed” have similar vectors even without shared keywords), while knowledge graphs capture explicit logical relationships (SSD → improves → Performance). During search, vector similarity finds semantically related content, and the knowledge graph provides reasoning paths to discover connected concepts and comprehensive answers. This combination enables both fuzzy semantic matching and precise logical reasoning.
Why AI indexing drives the chunk-sized and structured content recommendation?
When AI systems chunk content, they look for topic boundaries, complete thoughts, and logical sections. They analyze content for natural break points that preserve context and meaning. AI systems perform better when content is already organized into self-contained, meaningful units.
When you structure content with clear section breaks and complete thoughts, you do the chunking work for the AI. This ensures related information stays together and context isn’t lost during the indexing process.
What’s coming up next?
In the next blogpost of this series, I’ll dive into how generative AI and RAG-powered search reshape the way systems interpret user queries, as opposed to the traditional keyword-focused methods. Our current post showed that AI indexes content by meaning, through chunking, vector embeddings, and building concept networks. It’s equally important to highlight how AI understands what users actually mean when they search.