Like all tier-1 research universities, our institution has over 60 K students, 20k employees including teaching and research faculty, staff, part-time and temp. Over the years, multiple platforms have been adopted by various campus units to keep track on different sorts of employees’ data. Therefore it can be a little challenge when it comes to integrate data from different platforms about employees’ background info, like gender, years of service, position type, with data about their participation of professional development courses on campus.
I chose to use R to import the .csv files from two different data systems, and then reformat and combine them, to get an integrated data table for my analysis.
First we got the data from our training website. These data include two types: course participants only from the year of 2015 to 2017; and all employees on record from 2015 to 2017.
The first type data include: first name, last name, email address, department, course session, participate status (attended, cancel, and late cancel), course session date.
The second data include: First Name, Last Name, SupervisorInd (0 for non supervisory, 1 for supervisory). However, there is no department information in this data.
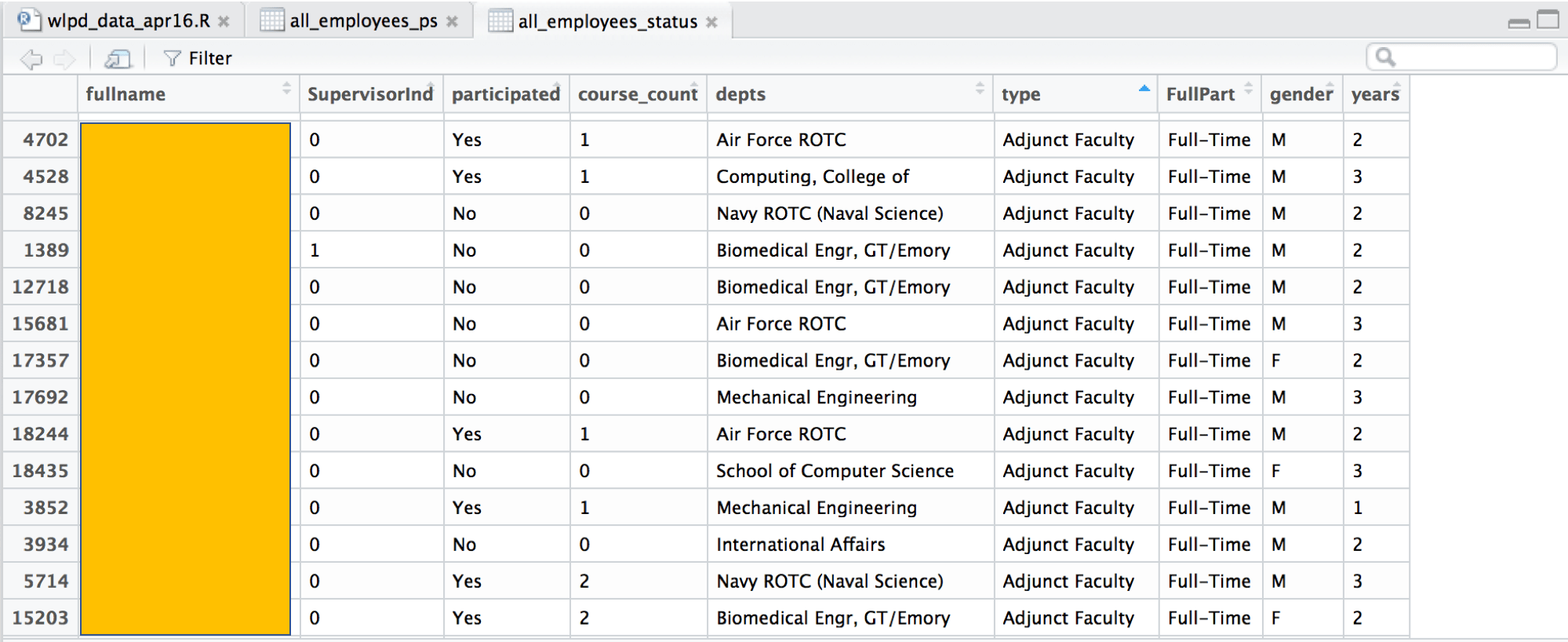
By merging two types data, I got my first version of the “final” table, including: full name, department, supervisoryInd, participation status (Y/N), and number of courses participated.
However, I want to know if the following factors would affect the participation status and the number of courses participated: gender, year of service, departments, type(staff, academic faculty, research faculty, adjunct faculty, tech temp,etc.), and full/part-time.
So I reached out to the admin of the campus employee record system. They kindly provided the data of employ who started within the years of 2015- 2017 with first time, last name, gender, type, full/part-time, departments, and they were very kind to compute the years of service as well.
From there I was able to create my second version of the final data table: