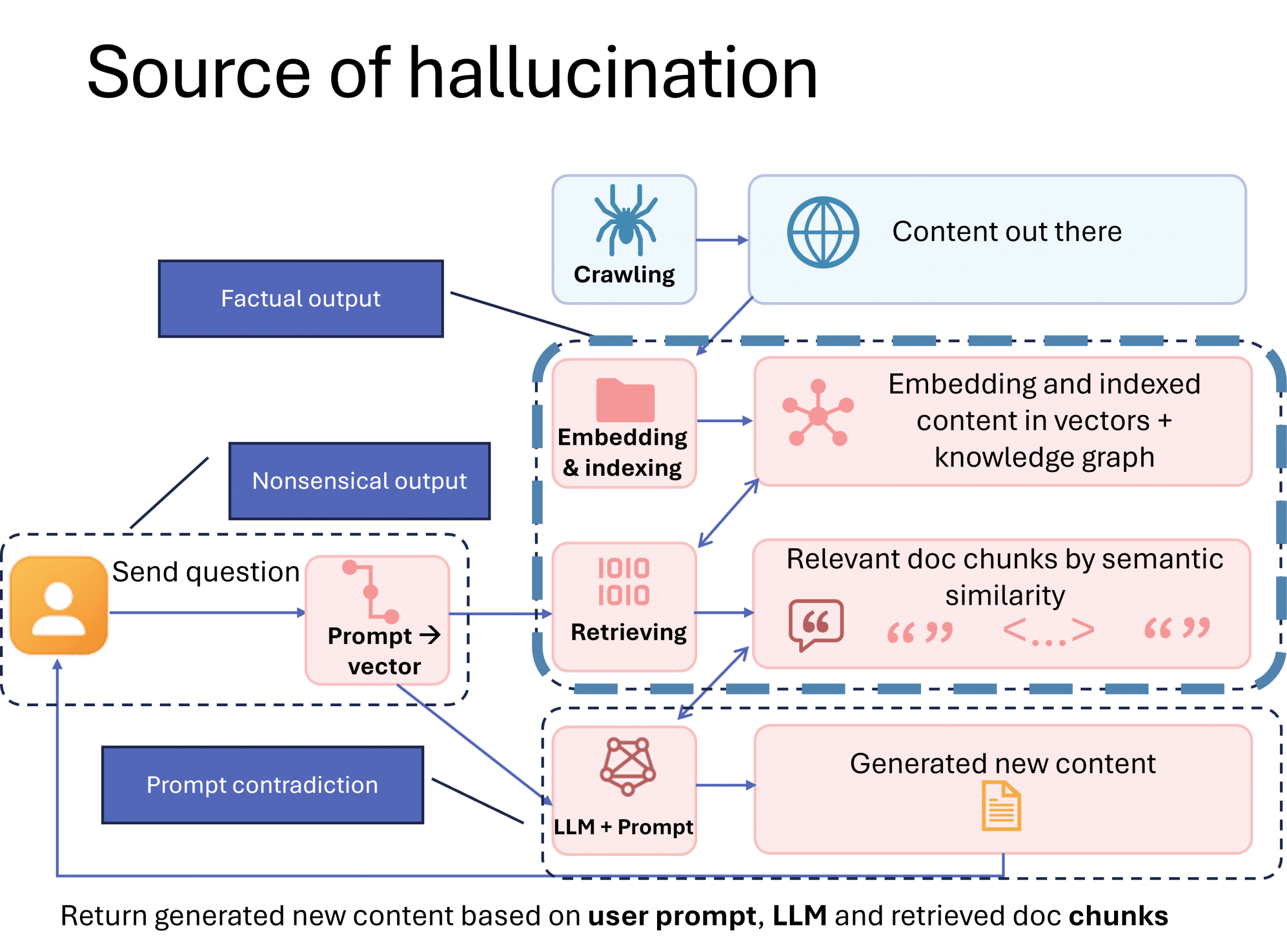
In my last blog post, I compared documentation formats across major tech companies and came to the conclusion:
Most modern developer-facing documentation is authored in Markdown, often paired with YAML or JSON metadata.
But when I dug deeper to look into the sources of the public-facing pages, I found:
- All documentation is published as HTML
- Search engines crawl and index the HTML, not the Markdown
- Even when a page includes a link to the underlying
.mdfile (like Microsoft Learn or React Native), search engines still ignore the Markdown
So the natural question is:
If Google and Bing only crawl HTML, why bother using Markdown at all?
It’s a fair question.
And the answer is:
Search engines don’t read the Markdown. However, using Markdown ensures the final HTML is clean, consistent, and easy for search engines to understand.
Let’s break down why.
1. Markdown creates consistent, semantic content that build systems can transform into clean, crawlable HTML
Markdown itself doesn’t “force” structure the way XML schemas do.
But when tech companies use Markdown, they use it inside a controlled publishing pipeline with:
- automated linting
- required metadata
- heading hierarchy rules
- link validation
- accessibility checks
- build-time transformations
Markdown limits what authors can do:
- no inline CSS
- no arbitrary fonts
- no invisible
<span>wrappers - no custom colors
- no inconsistent indentation
- no malformed HTML
Because Markdown is intentionally minimal, authors can’taccidentally introduce structural noise that breaks the final HTML.
Meanwhile, HTML authored through WYSIWYG tools often contains:
- messy nested tags
- inline styling
- inconsistent heading usage
- malformed lists
- copy-pasted formatting from Word/Google Docs
That HTML looks fine to humans but is unreliable for:
- SEO
- accessibility
- automated formatting
- AI extraction
- embedding pipelines
Markdown → parsed via a deterministic engine → produces stable, semantic HTML that search engines interpret correctly.
Search engines may crawl HTML — but that HTML is better because it comes from Markdown.
2. Markdown keeps documentation consistent across thousands of pages and contributors
Large documentation ecosystems involve:
- hundreds of writers
- thousands of pages
- frequent updates
- global teams
- contributor submissions from the community
If each author could format content however they wanted (as in WYSIWYG HTML systems), you’d quickly get:
- drift in formatting
- inconsistent UI
- broken headings
- unpredictable layouts
Markdown prevents this simply by being limited:
- headings are headings
- lists are lists
- code blocks are fenced
- emphasis is standardized
- content is always plain text
And because Markdown lives in Git, every change goes through:
- version control
- pull requests
- reviews
- diff tools
- automated lint checks
That level of governance is impossible in most HTML-based CMS editors.
3. Markdown is the source-of-truth for multi-channel publishing — not just HTML
HTML is only one of the outputs produced from Markdown.
Big tech companies use Markdown because from a single source file, the build pipeline can generate:
- SEO-optimized HTML
- JSON-LD (for schema.org metadata)
- in-product help panes
- mobile-friendly layouts
- downloadable PDFs
- interactive components (tabs, code toggles)
- localized versions
- sanitized versions for RAG
- internal knowledge base variants
If companies authored directly in WYSIWYG HTML, they would need separate versions of the same content for each channel.
Markdown eliminates that duplication.
You write once → the system generates everything.
4. Markdown is ideal for internal AI/RAG pipelines — even if public crawlers ignore it
Search engines crawl HTML. That’s fine.
But companies increasingly build:
- product Copilots
- in-app assistants
- enterprise RAG systems
- internal chatbot experiences
- developer help inside IDEs
These internal systems do not crawl the public HTML.
They ingest the source Markdown directly, because it provides:
- clean text
- predictable section boundaries
- easy chunking based on H2/H3/H4
- front matter metadata for filtering
- embedding-friendly content
- no UI noise
Markdown is simply a better substrate for retrieval than HTML.
And because these internal systems matter as much as (or more than) public search, Markdown becomes foundational.
5. Markdown supports extensibility and semantic enhancements that HTML cannot express cleanly
Modern documentation systems extend Markdown to carry semantics:
- Apple DocC adds directives for API symbols and tutorials
- Docusaurus (Meta) adds MDX for interactive components
- Microsoft Learn adds custom Markdown for notes, warnings, code tabs, and includes
These semantic hints help build:
- richer HTML
- structured data
- searchable API references
- component-based docs
- better embeddings for RAG
HTML could express these things, but only manually and inconsistently.
Markdown extensions ensure that structure is carried through the entire pipeline.
6. Markdown enables open collaboration — something HTML workflows do poorly
When documentation lives in Markdown files on GitHub:
- external users can fork the repo
- contributors can propose edits
- issues can be filed against specific lines
- reviewers can comment inline
- history is transparent
This has become the foundation for open developer documentation.
HTML-based CMSs rarely allow this level of collaboration without heavy engineering
Conclusion
Even though Google, Bing, and GPT-style models crawl only the rendered HTML:
- Big tech companies still author documentation in Markdown
- They pair it with YAML/JSON front matter
- Their build systems transform Markdown into high-quality, semantic HTML
- Their AI/RAG systems rely on the Markdown, not the HTML
- Their governance workflows depend on Markdown being in Git
- Their multi-channel publishing depends on Markdown as a single source of truth
In other words:
Markdown is the authoring format.
HTML is just one of the publishing formats.
One is the “source code.”
The other is the compiled artifact.